运营商栅格预测
前言¶
GeoHash编码原理¶
GeoHash 技术原理及应用实战[https://zhuanlan.zhihu.com/p/645078866]
简单来说,就是利用带有距离的索引对坐标进行编码,其索引与相对距离有关,索引重复度越大,两点距离越近
环境搭建¶
使用pytorch的图神经网络插件模块
此时跑demo会报错
cannot import name ‘container_abcs‘ from ‘torch._six‘
参考cannot import name ‘container_abcs‘ from ‘torch._six‘
1.8版本之后container_abcs被移除了。所以导入方式不同会出现这样的错误
修改源码(此方法权限不足时无法使用) 进入环境中torch_geometric的dataloader.py文件将
from torch._six import container_abs,string_classes,int_classes
替换为
import collections.abc as container_abcs
int_classes = int
string_classes = str
之后又报错
ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the ‘ssl’ module is compiled with OpenSSL 1.1.0h 27 Mar 2018.
解决办法
pip install urllib3==1.26.15
详解PYG¶
图数据:Data
-
x (torch.Tensor, optional) – Node feature matrix with shape [num_nodes, num_node_features]. (default: None) 节点与其特征
-
edge_index (LongTensor, optional) – Graph connectivity in COO format with shape [2, num_edges]. (default: None) 边序号
-
edge_attr (torch.Tensor, optional) – Edge feature matrix with shape [num_edges, num_edge_features]. (default: None) 每条边特征
-
y (torch.Tensor, optional) – Graph-level or node-level ground-truth labels with arbitrary shape. (default: None) 标签
-
pos (torch.Tensor, optional) – Node position matrix with shape [num_nodes, num_dimensions]. (default: None) 节点位置矩阵
-
**kwargs (optional) – Additional attributes.
通过 train_mask 和 test_mask 来实现训练集和测试集的划分
import torch_geometric.transforms as T
split = T.RandomNodeSplit(num_val=0.1, num_test=0.2)
构建自己的图数据集
import torch
from torch_geometric.data import InMemoryDataset
from Dataset import get_trainxy,get_trainedge,get_testx,get_testedge
from torch_geometric.data import Data
class MyOwnDataset(InMemoryDataset):
def __init__(self, root='./GNNdata', transform=None, pre_transform=None, pre_filter=None):
super().__init__(root, transform, pre_transform, pre_filter)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2']
@property
def processed_file_names(self): # 缓存的名字
return ['data.pt']
# def download(self):
# # Download to `self.raw_dir`.
# download_url(url, self.raw_dir)
# ...
def process(self):
# Read data into huge `Data` list. 这里是构建Data list的过程,也就是自己要改的地方
x, y = get_trainxy(norm='')
edge_index, edge_attr = get_trainedge()
edge_index = [torch.tensor(tensor, dtype=torch.long) for tensor in edge_index]
edge_attr = [torch.tensor(tensor, dtype=torch.float) for tensor in edge_attr]
data_list = []
for i in range(x.shape[0]):
data = Data(x=torch.FloatTensor(x[i]),
edge_index=edge_index[i],
edge_attr=edge_attr[i],
y=torch.FloatTensor(y[i]))
data_list.append(data)
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
运行完之后再所指定的root路径下会生成"raw/"和"process/"两个文件夹,raw故名思意也就是原始数据的意思,这里我们都在process里实现好了,故这个文件夹为空,'process/'文件夹可以理解为缓存,之后读取数据都会从这里读取而不用重新generate.
这次的数据为90天的栅格图,每张图有1140个节点,33维特征, 所以接着运行
dataset = MyOwnDataset()
# 会得到一个显示{MyOwnDataset:90}的变量,打开变量监视窗口可以看到这个dataset将所有图的节点,边全都垂直拼在了一起,例如x=[1140*90, 33] 其中的slice属性即代表每张图对应这个dataset的索引,如果有90张图, 每个属性的slice就有91个数
接着创建dataloader
train_loader = DataLoader(dataset, batch_size=5, shuffle=False)
# 当batch_size不为1时,迭代时的Data就是将batch个图垂直拼接起来,但多了一个batch:Tensor的属性,其中数据为{0..1...2...3..4} 相同的值代表一张图的数据,这里在一个batch里总共有五张图
至此就完成了数据集的载入
实验过程¶
数据预处理¶
LSTM¶
参考链接
基于 PyTorch + LSTM 进行时间序列预测(附完整源码)
LSTM的模型建立以及用LSTMCell构建模型的相关学习记录
循环神经是带有循环的网络,允许信息持续存在。就是当前的输出(y3)与不仅仅与当前的输入(x3)有关, 还和之前的输入(x1, x2)有关
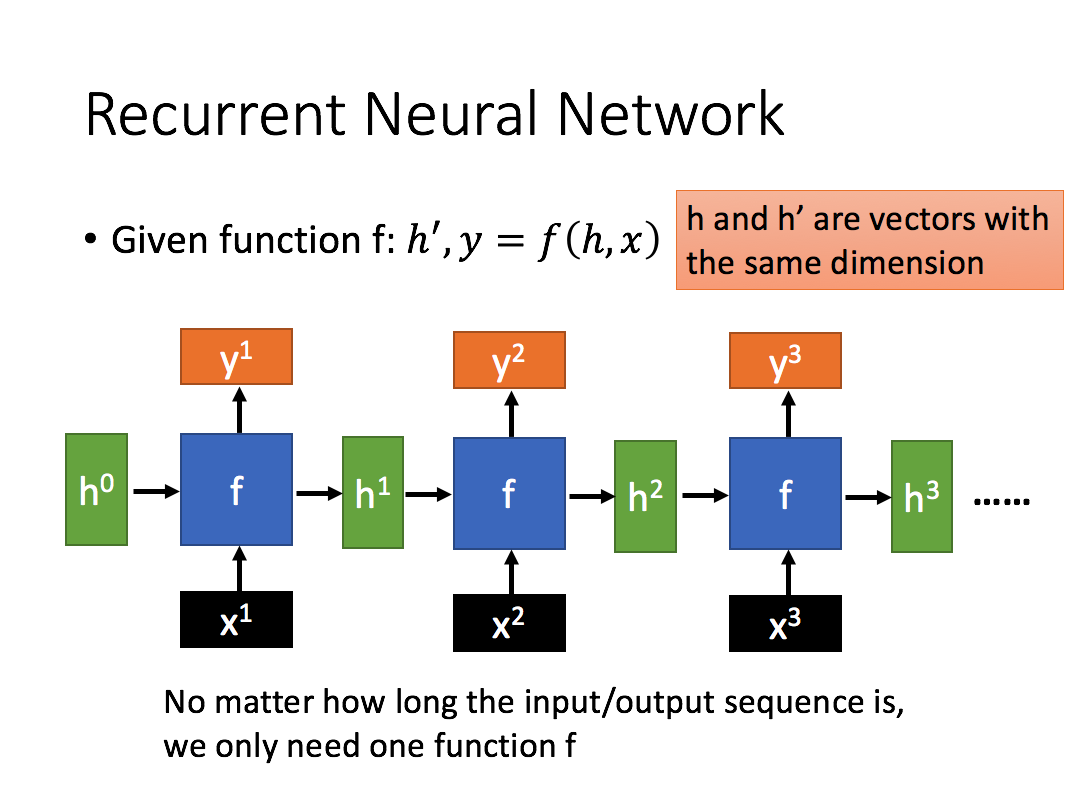
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
强烈推荐李宏毅老师的课: 李宏毅手撕LSTM
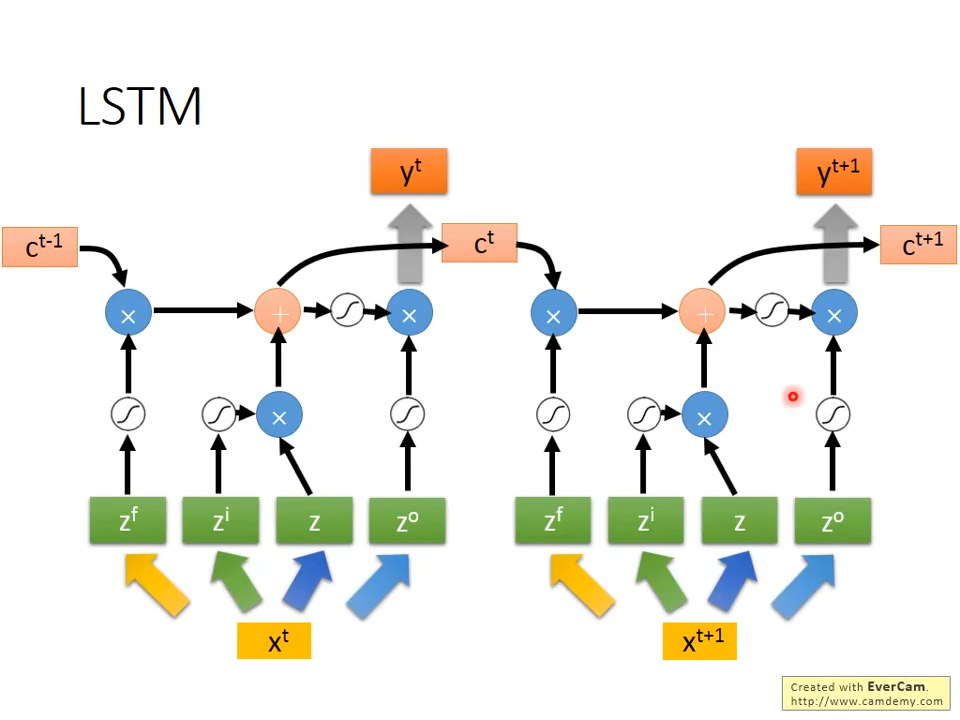
这里的粗箭头代表乘一个权重
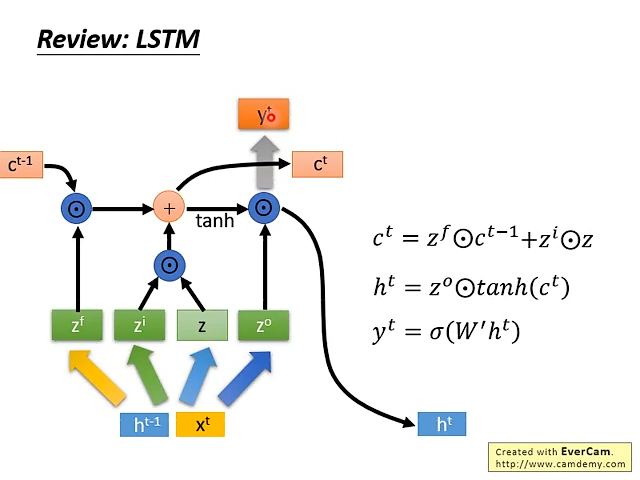
c的变化很小,h的变化很大
CNN+LSTM¶
参考链接
GNN+LSTM¶
参考开源 GNN-LSTM-based-Fusion-Model-for-Structural-Dynamic-Responses-Prediction
总结¶
特征工程处理要点
- 输入的特征要在每一维做归一化, 输出不需要做归一化