CUDA
CUDA Programming Guide¶
首先要先理解thread, block和grid的关系
官方文档图片 👇
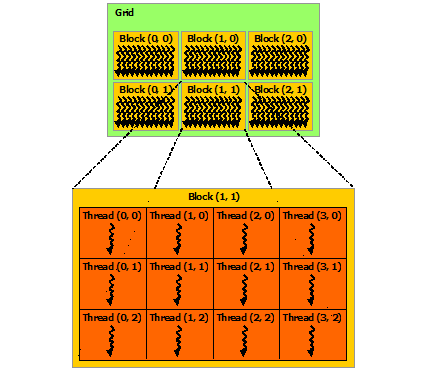
每个block的threads数量是有限制的,因为一个block的所有threads都驻留在同一个SM(流式多处理器核心)上,并且必须共享该核心有限的内存资源。在当前的GPU上,一个线程块可能包含多达1024个线程, 如果threads二维的话,可以定义为dim3 threads(16,16), 表示了有16*16=256个threads
一个kernal可以由多个形状相同的blocks执行,总threads数等于blocks*threadspreblock
多个blocks构成了grid, 用户需要自己设定blocks和threads的数量
block内的threads通过shared memory共享数据,并通过同步执行来协调内存访问。
更准确地说,可以通过调用__syncthreads()内部函数来指定内核中的同步点;__syncthreads()作为一个屏障,块中的所有线程必须在允许任何线程继续之前等待。共享内存给出了一个使用共享内存的例子。除了__syncthreads()之外,协作组API还提供了一组丰富的线程同步基元。
NVIDIA Compute Capability 9.0推出的新的层级结构--Thread Block Clusters: 类似于block中的threads保证在SM上被共同调度,cluster中的block也保证在GPU中的GPU处理集群(GPC)上被共同调度,说白了就是block和grid之间多了一级,但是grid的维度依旧是通过block计算的而不是通过cluster, cluster可以通过多种方式定义,这里不做展开,相关API一查就有
Memory Hierarchy(内存层级)¶
这节超重要!
官方文档图片 👇
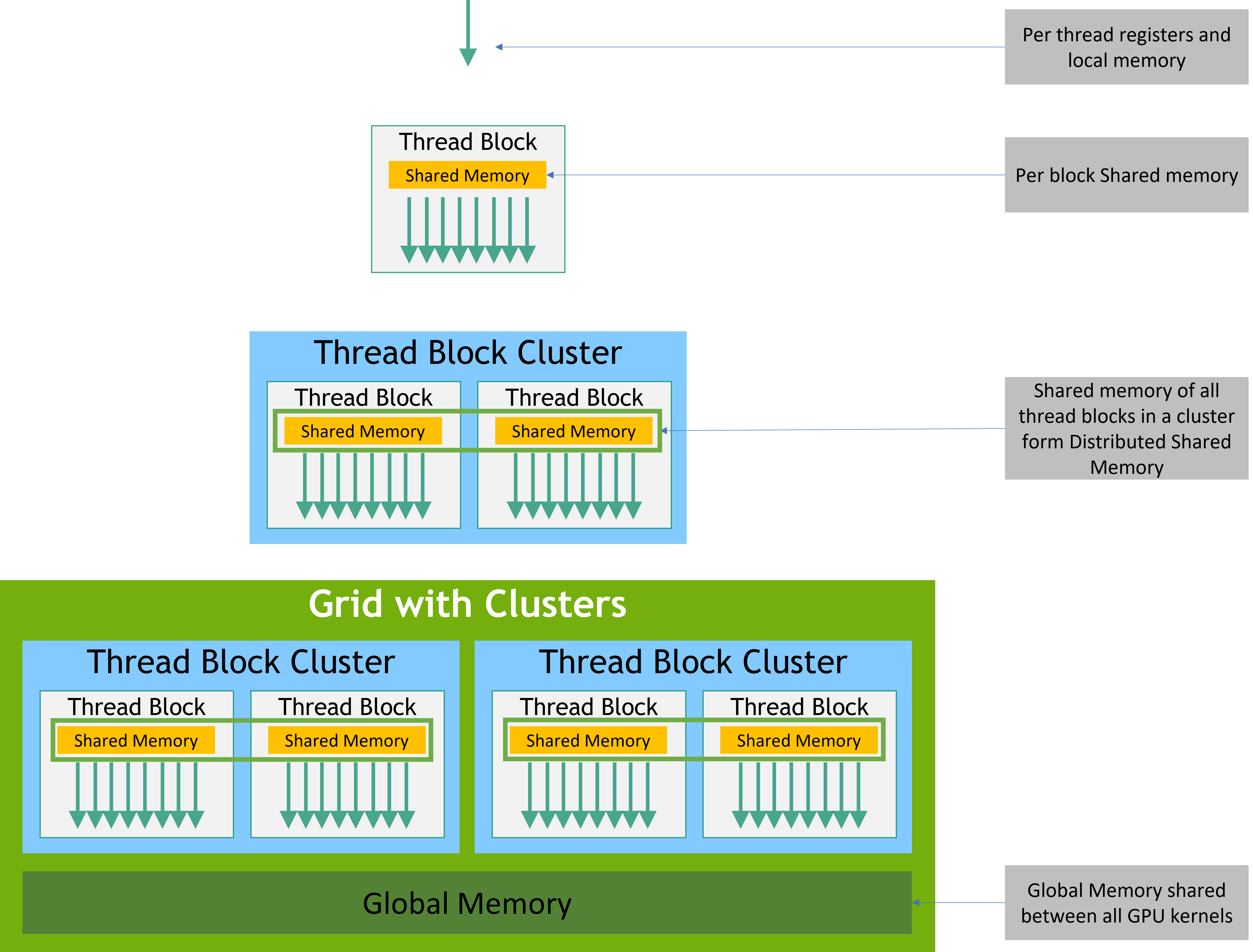
每个thread都有私有的本地内存。每个block具有block内所有thread都可见的共享内存(shared memory),并且与该block具有相同的生命周期, 所有thread访问相同的全局内存(global memory)。
Heterogeneous Programming(异构编程)¶
说白了就是cpu和gpu之间来回倒的编程
Asynchronous Operations(异步编程)¶
异步操作被定义为由CUDA thread 发起并由另一个thread 异步执行的操作。
trick¶
返回的pitch(stride)必须用于访问数组元素。